Auto-Labeler (AI Relevance Prediction)
Every (test search × document) pair receives an automated relevance probability using GPT-4o-mini — a Bayesian-style prior that our human safenet process refines later. These predictions populate the evaluation database that drives recall, precision, and confidence metrics.
PostgreSQLVespa RetrievalGPT-4o-mini PriorCloud SQL StorageEvaluation Baseline
Flow Overview
Process Flow (Search × Document → Relevance Label)
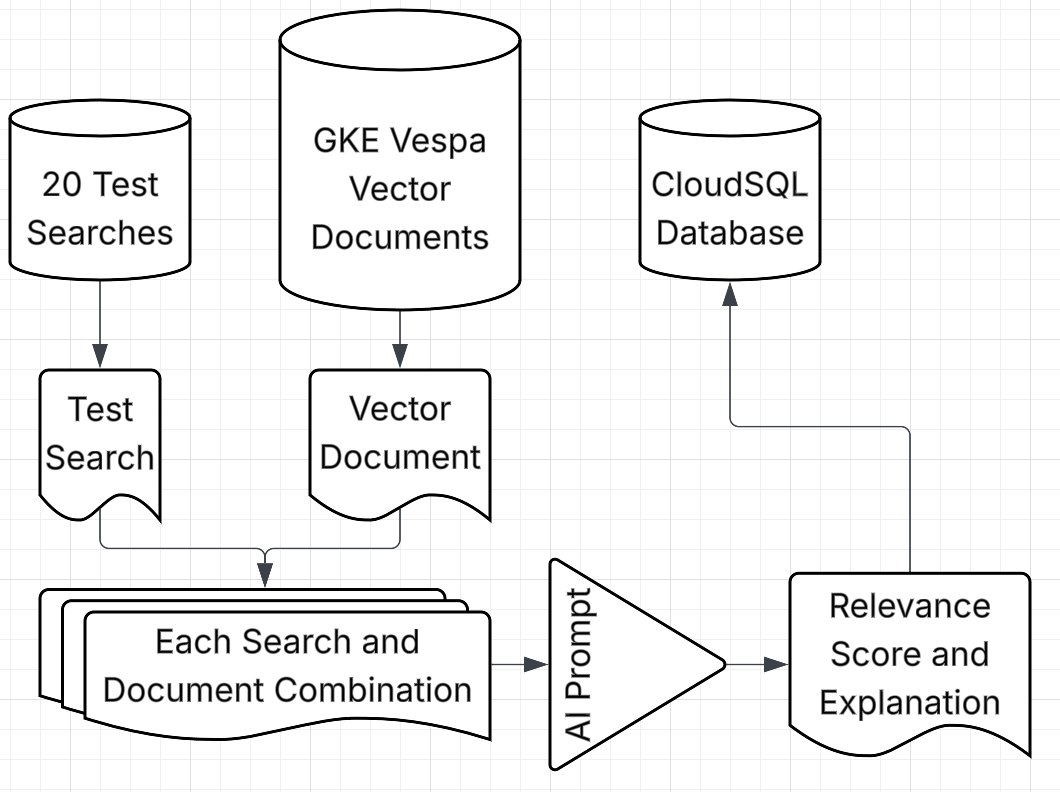
Test searches are paired with each Vespa document, scored by GPT-4o-mini, and persisted to Postgres for human collaborative verification and algorythmic evaluation.
Prompt & Output
Prompt Example
system: "You are an academic relevance judge. Given a search query and a paper (title + abstract), estimate the probability this paper is relevant to the query."
user:
"""
Query: {query_text}
Title: {doc_title}
Abstract: {doc_abstract}
"""
assistant:
{"Relevance_Probability": 0.0-1.0, "Reason": "..."}
model: gpt-4o-miniSample output
{
"query_text": "graph neural networks",
"title": "Efficient Retrieval for LLMs",
"relevance_prob": 0.86,
"reason": "Strong overlap on retrieval and indexing; applicable techniques.",
"model": "gpt-4o-mini",
"labeled_at": "2025-03-11T10:22:00Z"
}Probability Distribution
Distribution of Predicted Relevance (label-aware
prob_relevant)Snapshot from
pair_labels (8,700 pairs). Most pairs land in the 0–0.4 range (low probability of relevance) — expected because most retrieved candidates are negatives. Human consensus on the next page calibrates thresholds and confidence.Distribution Table (Static Snapshot)
| Bin | Count | Percent |
|---|---|---|
| 0–0.2 | 6,085 | 69.9% |
| 0.2–0.4 | 2,264 | 26.0% |
| 0.4–0.6 | 88 | 1.0% |
| 0.6–0.8 | 60 | 0.7% |
| 0.8–1.0 | 203 | 2.3% |
| Total | 8,700 | 100.0% |
To refresh live, run the width_bucket query over
prob_relevant and update these bins.Collaborative Human Safety Net!
From AI-generated relevance probabilities to human agreement and calibrated confidence.
0:00 / 0:00